
RAG (Retrieval-Agumented Generation)
이번에 볼 논문은 https://arxiv.org/abs/2005.11401 으로 2020년도에 NeurIPS에 출판된 논문이다.
제목에 포함된 대로 NLP에 검색(Retrieval)이 추가된(Agumented) 생성모델이다.
RAG은 LLM model의 성능을 비약적으로 상승시키는데 유용한 방법론이다. 특히나 이번에 챗봇에 대해 공부하면서 더욱 자세히 보게 되었다. 매우 유용한 방법론이고, 기존 LLM의 한계점인 Dataset과, Hallucination을 해결하는데 효과적이라는 생각이 들었다.
0. Abstract
Large Language model 에서는 학습된 정보를 parameter에 저장한다. 학습된 parameter들을 fine-tuning시켜 down-stream NLP 작업에 적용한다. 하지만 정보를 접근하거나, 해당 정보를 조작하는 과정은 굉장히 복잡하고 어렵다.
→모든 정보들이 parameter에 저장되어 있기에, 특정 지식을 기반으로 하는 knowledge-intensive task에서 한계를 가진다.
RAG에서는 기존 parametric memory와 non-parametric memory를 둘다 사용하여 지식을 기반하여 성능 높은 답변을 도출한다.

2가지 RAG 형식을 비교한다.
1. 동일한 검색된 단락을 기반으로 비교
2. 토큰당 서로다른 단락 사용
3가지 domain에 대해 QA를 통해 성능을 검증하였으며, 특정 지식 검색 및 정보 추출의 성능이 월등히 뛰어났다.

유투브와 초록을 정리한 내용은 위의 도식과 같다.
"I don't know"를 답변할 수 있는 점은 굉장히 유의미한 성과이다. 하지만 확실한 정보임에도 불구하고 sufficient 한 data가 없어
"I don't know" 답변을 하는 경우가 발생할 수 있으므로 model 설정을 잘해야한다
1. Introduction
학습된 language model들은 외부 메모리를 참조하지 않고도 parameterized 되기에 정보를 함축할 수 있다. 하지만 학습된 데이터들은 그들의 정보를 확장하거나, 수정하기가 어렵기에 Hallucination을 유발할 수 밖에 없다. 해당 논문에서는 기존 paramterized된 방법과, memory를 이용하여 un-parameterized 된 정보를 결합하여 정보의 확장과 수정을 용이하게하여 down-stream NLP task에서의 성능을 높인다.
transformer가 적용된 seq2seq를 학습시켜 parameterized된 모델을 제시하고, Wikipedia를 이용하여 정보 vector을 이용하여 non-parametrized memory를 생성한다. 두가지 정보는 학습된 end-to-end probabilistic model을 사용하여 제공한다.

retrieval ((Dense Passage Retrieval, DPR))을 이용하여 latent document를 생성하고, MIPS를 이용하여 쿼리 벡터와 내적을 통하여 가장 적절한 정보를 도출함과 동시에 순위(top-K)를 매긴다. top-K의 우선순위를 매길때에는 전체 답변 단위로 매기기도 하고, Token 단위로 매기기도 한다. 원래의 query와 latent document를 결합하여 사전 학습된 seq2seq의 input으로 하여 최종 output을 도출한다. 학습과정에서 generator와 retriever 모두 학습이 진행된다.
RAG model의 knowledge-intensive task측면의 3가지 domain ((Natural Question, WebQuestion, CuratedTrec))에 대한 QA에서 높은 성능을 보여주었다. 특히나 TriviaQA에서 압도적으로 높은 성능을 도출하였다.
triviaQA : Reading Comprehension Dataset https://aclanthology.org/P17-1147/
2. Method
위에서 본 Figure 1처럼 input $x$ 을 이용하여 document $z$ 를 검색한다. 검색으로 부터 얻은 추가 정보를 이용하여 target sequence $y$ 를 생성한다.
RAG 모델은 두가지로 구성되어있다.
1) 검색과정 ((retriever))
$p_\eta (z|x)$ 의 변수인 $\eta$ 를 이용하여 주어진 쿼리 $x$ 에 대해 top-K turncated 분포를 반환한다.
2)생성과정 ((generator))
$p_\theta (y_i|x,z,y_{1:i-1})$ 을 이용하여 $i-1$ 번째 까지 생성된 답변, 검색 문자열 $z$ , 입력 문자열인 $x$ 을 이용하여을 이용하여 생성한다.
2.1 retrieve marginalize model
검색과정과 생성과정을 모두 학습시키기 위해서 검색된 문서의 벡터를 잠재변수 latent variable 로 생각한다. 생성된 텍스트의 분포를 판단할 수 있도록 두가지 상세 모델을 제안한다. 즉 retrieve된 document을 marginalize 하기 위해 다음의 2가지 모델을 사용한다.
1) RAG-Sequence Model
동일한 검색 문서를 이용하여 답변 sequence를 완성한다. 그럼 해당 문서의 검색 내용을 단일 latent variable로 생각할 수 있으며, top-k approximation 을 이용하여 seq2seq 확률을 구할 수 있다. 따라서 각 문서의 차이를 판단할 수 있다.

다음의 수식을 자세하게 살펴보면, top-k에 해당하는 document z를 이용하여 응답 y를 생성한다. 제일 오른쪽의 수식은 단지 순차적인 sequence output을 이용하여 생성한다는 점이다. 하나의 document $z$ 에 대해서 sequence 안의 모든 token에 대한 확률을 계산한 뒤에, 모든 값을 더하여 tok-k approximation을 수행할 수 있도록 한다.
2)RAG-Token Model
다른 검색 문서를 이용하여 답변 sequence를 완성한다. 이러한 과정을 통하여 여러 document의 latent variable의 정보를 이용하여 답변을 생성할 수 있다.
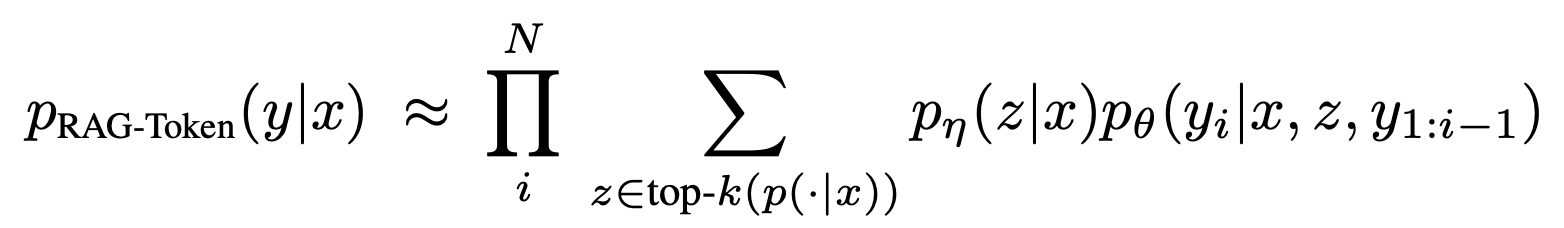
위의 RAG Sequence Model와의 가장 큰 차이점의 경우 RAG Sequence Model의 경우 정해져있는 하나의 document $z$ 을 이용하여 생성한 반면 RAG Token Model의 경우 다양한 document $z$ 을 이용하여 먼저 marginalize 하여 output sequence를 생성한다는 점이 다르다.
따라서 Sequence model은 document를 sequence 단위로 고려하고, Token model은 각 document를 token 단위로 고려하여 output sequence을 생성한다.
2.2 Retrieve : DPR
retrieve 하는 $p_\eta (z|x)$ 으로 DPR을 사용한다. DPR은 bi-encoder구조이며 아래와 같이 수식으로 나타낼 수 있다.

document 정보인 $d(z)$ 는 $BERT_{BASE}$ 를 이용하여 encoding되었으며, query인 $q(x)$ 는 $BERT_{BASE}$ 를 이용하여 encoding된다. 여기서 x는 input을 의미하며 각각 encoding할때 사용되는 BERT의 parameter는 다르다.
두개의 encoding 되어있는 벡터화 되어있는 두가지 쿼리의 MIPS연산을 이용하여 상응하는 답을 document를 찾는다. MIPS: Maximum Inner Product Search 연산에서는 두벡터의 내적을 이용하여 연관성을 파악한다. 이후 내적값이 높은 순서대로 파악하는 top-k를 골라 retrieve한다.
다음과 같은 방법을 사용하므로써, sub-linear time의 효율성을 가진다.
2.3 Generator : BART
생성 부분은 어느 encoder-decoder모델을 사용해도 된다. 해당 논문에서는 4억개의 parameter을 가지는 BART model을 사용하였다.
이때 input에 해당하는 $x$ 와 retrieve한 $z$ 를 합칠때에는 단순히 concatenate한다.
해당 논문에서 BART를 사용한 이유로는 denosing 목적을 가지고 있으며, 비슷한 prarmeter을 가지고 있는 T5에 비해 성능이 뛰어나기 때문이라고 말했다.
2.4 Training
RAG에서는 DPR 기반의 retriever와 BART을 사용하는 genertator는 동시에 training한다.
학습하는 과정에서 어떠한 document가 retrieve가 되어야 하는지는 direct supervision은 주어지지 않는다. 오직 fine-tuning training을 위한 input 과 output 말뭉치를 사용하여 NLL : Negative Log-Likelihood를 줄이기 위한 방향으로 움직인다.
즉, 어떠한 document를 retrive 해야하는지 정답은 제공되지 않지만, NLL을 사용하여 더욱 좋은 output을 산출할 수 있도록 한다.
위의 3.Retrieve:DPR 에서 query와 document를 각각 encoding 하는 BERT 두개를 사용한다고 하였다. 해당 연구에서는 REALM에서 진행했던 방식인 document encoder을 update하는 방식은 비용이 많이 들고, 비약적인 성능향상이 동반되지 않기에, 고정한다고 하였다. 따라서 오직 $BERT_{q}$ 와 $BART$ generator만 fine-tuning한다고 하였다.
2.5 Decoding
RAG-Sequence 와 RAG-Token의 모델은 위에서 설명했듯이 distribution을 측정하는 기준이 다르므로, token decoding : $arg\ max_yp(y|x)$ 하는 과정에서 차이점이 존재한다.
RAG_Token와 RAG_Sequence의 Decoding을 설명하기 전에 먼저 Beam Search에 대해서 알고가자.
보통 seq2seq 모델에서는 다음 token을 선택하는 과정에서 SoftMax함수를 이용한 Greedy Decoding방식을 사용한다.

가장 높은 확률을 가질 Token을 선택하기에 시간적인 측면에서는 유리할 수 있으나, 답이 한번이라도 틀릴 경우 이전 예측이 중요한 디코딩에서는 치명적 단점을 가지게 된다.
이러한 단점을 극복하기 위해 나온 것이 Beam Search이다.
모든 것을 고려하고 그다음 token을 선택하면 가장 좋은 방식이지만, 시간 복잡도 측면으로는 불가능한 일이다.
Beam Search에서는 해당 시점에서 유망한 Beam (이하 K)개 만큼을 골라서 적용하는 방법이다.
누적의 확률을 계산하여 이후의 가장 확률이 높은 token을 선택한다.

먼저 RAG_Token의 Decoding과정이다.

RAG_Token 모델의 경우 token별로 marginalize 하기에 기존 seq2seq 방식과 유사하다.
다만 Token 별로 document의 distribution을 계산하여 모든 값을 더하여 document의 정보를 반영한다.
즉, 생성하는 시점에 Document의 marginalize정보가 동시에 들어가기에 standard beam search처럼 사용할 수 있다.
다만 RAG_Sequence는 기존에 사용하던 per-token liklihood를 사용할 수 없다.
위에서 보았던 수식을 다시 한번 살펴보면, document의 margin을 구하기 전에, sequence를 끝까지 생성한다. 이후에 Document와 marginalize한다. 따라서 기존에 사용하던 beam search를 진행할 수 없다.

input $x$에 대해서 top-k retrieve를 진행한다. k=3 이기에 가장 유사성이 높은 3개의 document를 이용하는 것을 확인할 수 있다.
이후 각각의 document에 대하여 input $x$ 와 document $z$ 별로 확률이 높은 $k$ 개의 sequence를 도출한다. 그러면 각각의 document에 대해서 output $p(y|x,z)$ 를 확인할 수 있다.

결과를 보면 다음과 같다.
그런데 여기서 문제를 살펴보면, 빨간색의 값들은 beam search를 하는 과정에서 나타나지 않은 값들이다.
예를들어 $p(y_2 | x, z_2 )$ 의 경우 $x$ 와 $z_2$가 주어졌을때 output 으로 $y2$ 가 나타날 확률이다. 그러나 실질적으로는 좌측상단처럼 $z_2$ 로 부터는 $y_1, y_2, y_5$ 만이 생성되었다.
즉 상위 3개의 항목에 속하지 않는경우 확률을 알 수 없다는 한계가 발생한다.

이러한 문제를 해결하기 위해서는 $y_1, y_2, y_5$ 와 같이 발견되지 않은 값들에 대해서 추가적으로 model에 넣어서 연산이 진행될 수 있도록 해야한다. 논문에서는 이러한 문제점을 해결하기 위해 0으로 넣어 연산을 진행하는 Fast Decoding을 진행한다.
3. Experiment & Result
해당 연구에서는 다양한 knowledge-intensive task에 실험을 진행하였다.
외부 데이터를 사용하기 위해 nonparametric 데이터로 Wikipedia (2018년까지) 를 사용하였으며, 100-word 말뭉치로 잘라 210억개의 document를 구성하였다. MIPS index는 FAISS를 이용하여 만들었다. top-k document를 찾는 과정에서의 k 값은 5 또는 10을 사용하였다.
3.1 Open-domain Question Answering
해당 연구에서는 RAG가 NLL을 최소하도록 학습을 진행하였다. 비교군으로는 유명한 다른 검색을 사용하는 QA paradigm 모델들, parametric knowledge를 사용하는 모델 등과 비교를 하였다. 비교 domain으로는 총 4가지를 선택하였으며, Natural Question, TriviaQA, WebQustion, CuratedTrec이 존재한다.

Closed Book은 parametric 되어있는 모델과의 비교이며, Open Book 모델의 경우 RAG와 동일하게 Retrieve하여 정보를 찾는 모델에 해당한다. 대부분의 domain에서 RAG 모델의 성능이 높은 것을 알수 있다.
3.2 Abstractive Question Answering
RAG 모델의 경우 단순히 QA 모델에서 검색하는 능력을 벗어나서, 자유로운 형식에 대한 추상적인 질문에 대한 답변도 가능하다.
RAG의 언어 생성 능력을 판단 하기 위해서 NLG model중 MSMARCO NLG task v2.1를 사용하였다고 하였다. 해당 테스트에서는 각 질문에 대해서 10개의 최상 단락을 가져오고, 답변 출처의 원문 또한 anootated되어있다고 하였다.

답변에 필요한 특정 정보를 가진 gold passage를 이용하였을때 SotA 모델의 성능이 나온다라고 하였다. RAG모델의 경우
1) 답변에 필요한 Gold passage에 접근이 가능하다.
2) 많은 답변이 Gold passage 접근 없이 답변이 불가능하다는점
3) 모든 질문들이 Wikipedia 만을 사용해서는 답변할 수 없다는 점
의 시사점을 보아 SotA 모델의 성능에 거의 근접한 것을 확인할 수 있었다. 또한 RAG를 이용하여 생성한 답변이 Hallucination을 덜 일으키며, 더욱 다양하다.
3.3 Jeopardy Question Generation
open-domain에 등록되지 않은 QA 의 질문들 또한 테스트하여, 텍스트 생성에 중점을 맞춰 질문을 생성하는 능력을 보았다. Jeopardy는 주어진 정보에 대한 사실들을 바탕으로 질문을 생성해주는 과정을 얘기한다.
예를들면 "The World Cup"의 답변을 가지는 "In 1986 Mexico scored as the first country to host this international sports competition twice."라는 질문 결과를 이끌어 낼 수 있어야 한다.
위의 Table 2를 확인해보면, 질문을 생성해내는 능력에 대해서 RAG가 뛰어나다는 것을 확인할 수 있다.
3.4 Fact Verificaiton
FEVER은 답변의 데이터의 출처가 어디인지 True, False, 모르는지의 여부또는 부족한지 Classification하는 과정이다. 이러한 모델은 RAG가 gneration 측면이 아닌 classification에 대한 성능을 측정한다. 우리는 FEVER 클래스 라벨을 총 3개로 하여 (supports, refutes, or not enough info) 분류를 진행하였다.
Table 2를 확인해보면 72.5%의 정확성으로 sota에 비해 다른 목적을 가지고 있으메도 충분히 높은 것을 확인할 수 있다.
'논문 Review' 카테고리의 다른 글
RAG (Retrieval-Agumented Generation)
이번에 볼 논문은 https://arxiv.org/abs/2005.11401 으로 2020년도에 NeurIPS에 출판된 논문이다.
제목에 포함된 대로 NLP에 검색(Retrieval)이 추가된(Agumented) 생성모델이다.
RAG은 LLM model의 성능을 비약적으로 상승시키는데 유용한 방법론이다. 특히나 이번에 챗봇에 대해 공부하면서 더욱 자세히 보게 되었다. 매우 유용한 방법론이고, 기존 LLM의 한계점인 Dataset과, Hallucination을 해결하는데 효과적이라는 생각이 들었다.
0. Abstract
Large Language model 에서는 학습된 정보를 parameter에 저장한다. 학습된 parameter들을 fine-tuning시켜 down-stream NLP 작업에 적용한다. 하지만 정보를 접근하거나, 해당 정보를 조작하는 과정은 굉장히 복잡하고 어렵다.
→모든 정보들이 parameter에 저장되어 있기에, 특정 지식을 기반으로 하는 knowledge-intensive task에서 한계를 가진다.
RAG에서는 기존 parametric memory와 non-parametric memory를 둘다 사용하여 지식을 기반하여 성능 높은 답변을 도출한다.
2가지 RAG 형식을 비교한다.
1. 동일한 검색된 단락을 기반으로 비교
2. 토큰당 서로다른 단락 사용
3가지 domain에 대해 QA를 통해 성능을 검증하였으며, 특정 지식 검색 및 정보 추출의 성능이 월등히 뛰어났다.
유투브와 초록을 정리한 내용은 위의 도식과 같다.
"I don't know"를 답변할 수 있는 점은 굉장히 유의미한 성과이다. 하지만 확실한 정보임에도 불구하고 sufficient 한 data가 없어
"I don't know" 답변을 하는 경우가 발생할 수 있으므로 model 설정을 잘해야한다
1. Introduction
학습된 language model들은 외부 메모리를 참조하지 않고도 parameterized 되기에 정보를 함축할 수 있다. 하지만 학습된 데이터들은 그들의 정보를 확장하거나, 수정하기가 어렵기에 Hallucination을 유발할 수 밖에 없다. 해당 논문에서는 기존 paramterized된 방법과, memory를 이용하여 un-parameterized 된 정보를 결합하여 정보의 확장과 수정을 용이하게하여 down-stream NLP task에서의 성능을 높인다.
transformer가 적용된 seq2seq를 학습시켜 parameterized된 모델을 제시하고, Wikipedia를 이용하여 정보 vector을 이용하여 non-parametrized memory를 생성한다. 두가지 정보는 학습된 end-to-end probabilistic model을 사용하여 제공한다.
retrieval ((Dense Passage Retrieval, DPR))을 이용하여 latent document를 생성하고, MIPS를 이용하여 쿼리 벡터와 내적을 통하여 가장 적절한 정보를 도출함과 동시에 순위(top-K)를 매긴다. top-K의 우선순위를 매길때에는 전체 답변 단위로 매기기도 하고, Token 단위로 매기기도 한다. 원래의 query와 latent document를 결합하여 사전 학습된 seq2seq의 input으로 하여 최종 output을 도출한다. 학습과정에서 generator와 retriever 모두 학습이 진행된다.
RAG model의 knowledge-intensive task측면의 3가지 domain ((Natural Question, WebQuestion, CuratedTrec))에 대한 QA에서 높은 성능을 보여주었다. 특히나 TriviaQA에서 압도적으로 높은 성능을 도출하였다.
triviaQA : Reading Comprehension Dataset https://aclanthology.org/P17-1147/
2. Method
위에서 본 Figure 1처럼 input
RAG 모델은 두가지로 구성되어있다.
1) 검색과정 ((retriever))
2)생성과정 ((generator))
2.1 retrieve marginalize model
검색과정과 생성과정을 모두 학습시키기 위해서 검색된 문서의 벡터를 잠재변수 latent variable 로 생각한다. 생성된 텍스트의 분포를 판단할 수 있도록 두가지 상세 모델을 제안한다. 즉 retrieve된 document을 marginalize 하기 위해 다음의 2가지 모델을 사용한다.
1) RAG-Sequence Model
동일한 검색 문서를 이용하여 답변 sequence를 완성한다. 그럼 해당 문서의 검색 내용을 단일 latent variable로 생각할 수 있으며, top-k approximation 을 이용하여 seq2seq 확률을 구할 수 있다. 따라서 각 문서의 차이를 판단할 수 있다.
다음의 수식을 자세하게 살펴보면, top-k에 해당하는 document z를 이용하여 응답 y를 생성한다. 제일 오른쪽의 수식은 단지 순차적인 sequence output을 이용하여 생성한다는 점이다. 하나의 document
2)RAG-Token Model
다른 검색 문서를 이용하여 답변 sequence를 완성한다. 이러한 과정을 통하여 여러 document의 latent variable의 정보를 이용하여 답변을 생성할 수 있다.
위의 RAG Sequence Model와의 가장 큰 차이점의 경우 RAG Sequence Model의 경우 정해져있는 하나의 document
따라서 Sequence model은 document를 sequence 단위로 고려하고, Token model은 각 document를 token 단위로 고려하여 output sequence을 생성한다.
2.2 Retrieve : DPR
retrieve 하는
document 정보인
두개의 encoding 되어있는 벡터화 되어있는 두가지 쿼리의 MIPS연산을 이용하여 상응하는 답을 document를 찾는다. MIPS: Maximum Inner Product Search 연산에서는 두벡터의 내적을 이용하여 연관성을 파악한다. 이후 내적값이 높은 순서대로 파악하는 top-k를 골라 retrieve한다.
다음과 같은 방법을 사용하므로써, sub-linear time의 효율성을 가진다.
2.3 Generator : BART
생성 부분은 어느 encoder-decoder모델을 사용해도 된다. 해당 논문에서는 4억개의 parameter을 가지는 BART model을 사용하였다.
이때 input에 해당하는
해당 논문에서 BART를 사용한 이유로는 denosing 목적을 가지고 있으며, 비슷한 prarmeter을 가지고 있는 T5에 비해 성능이 뛰어나기 때문이라고 말했다.
2.4 Training
RAG에서는 DPR 기반의 retriever와 BART을 사용하는 genertator는 동시에 training한다.
학습하는 과정에서 어떠한 document가 retrieve가 되어야 하는지는 direct supervision은 주어지지 않는다. 오직 fine-tuning training을 위한 input 과 output 말뭉치를 사용하여 NLL : Negative Log-Likelihood를 줄이기 위한 방향으로 움직인다.
즉, 어떠한 document를 retrive 해야하는지 정답은 제공되지 않지만, NLL을 사용하여 더욱 좋은 output을 산출할 수 있도록 한다.
위의 3.Retrieve:DPR 에서 query와 document를 각각 encoding 하는 BERT 두개를 사용한다고 하였다. 해당 연구에서는 REALM에서 진행했던 방식인 document encoder을 update하는 방식은 비용이 많이 들고, 비약적인 성능향상이 동반되지 않기에, 고정한다고 하였다. 따라서 오직
2.5 Decoding
RAG-Sequence 와 RAG-Token의 모델은 위에서 설명했듯이 distribution을 측정하는 기준이 다르므로, token decoding :
RAG_Token와 RAG_Sequence의 Decoding을 설명하기 전에 먼저 Beam Search에 대해서 알고가자.
보통 seq2seq 모델에서는 다음 token을 선택하는 과정에서 SoftMax함수를 이용한 Greedy Decoding방식을 사용한다.
가장 높은 확률을 가질 Token을 선택하기에 시간적인 측면에서는 유리할 수 있으나, 답이 한번이라도 틀릴 경우 이전 예측이 중요한 디코딩에서는 치명적 단점을 가지게 된다.
이러한 단점을 극복하기 위해 나온 것이 Beam Search이다.
모든 것을 고려하고 그다음 token을 선택하면 가장 좋은 방식이지만, 시간 복잡도 측면으로는 불가능한 일이다.
Beam Search에서는 해당 시점에서 유망한 Beam (이하 K)개 만큼을 골라서 적용하는 방법이다.
누적의 확률을 계산하여 이후의 가장 확률이 높은 token을 선택한다.
먼저 RAG_Token의 Decoding과정이다.
RAG_Token 모델의 경우 token별로 marginalize 하기에 기존 seq2seq 방식과 유사하다.
다만 Token 별로 document의 distribution을 계산하여 모든 값을 더하여 document의 정보를 반영한다.
즉, 생성하는 시점에 Document의 marginalize정보가 동시에 들어가기에 standard beam search처럼 사용할 수 있다.
다만 RAG_Sequence는 기존에 사용하던 per-token liklihood를 사용할 수 없다.
위에서 보았던 수식을 다시 한번 살펴보면, document의 margin을 구하기 전에, sequence를 끝까지 생성한다. 이후에 Document와 marginalize한다. 따라서 기존에 사용하던 beam search를 진행할 수 없다.
input
이후 각각의 document에 대하여 input
결과를 보면 다음과 같다.
그런데 여기서 문제를 살펴보면, 빨간색의 값들은 beam search를 하는 과정에서 나타나지 않은 값들이다.
예를들어
즉 상위 3개의 항목에 속하지 않는경우 확률을 알 수 없다는 한계가 발생한다.
이러한 문제를 해결하기 위해서는
3. Experiment & Result
해당 연구에서는 다양한 knowledge-intensive task에 실험을 진행하였다.
외부 데이터를 사용하기 위해 nonparametric 데이터로 Wikipedia (2018년까지) 를 사용하였으며, 100-word 말뭉치로 잘라 210억개의 document를 구성하였다. MIPS index는 FAISS를 이용하여 만들었다. top-k document를 찾는 과정에서의 k 값은 5 또는 10을 사용하였다.
3.1 Open-domain Question Answering
해당 연구에서는 RAG가 NLL을 최소하도록 학습을 진행하였다. 비교군으로는 유명한 다른 검색을 사용하는 QA paradigm 모델들, parametric knowledge를 사용하는 모델 등과 비교를 하였다. 비교 domain으로는 총 4가지를 선택하였으며, Natural Question, TriviaQA, WebQustion, CuratedTrec이 존재한다.
Closed Book은 parametric 되어있는 모델과의 비교이며, Open Book 모델의 경우 RAG와 동일하게 Retrieve하여 정보를 찾는 모델에 해당한다. 대부분의 domain에서 RAG 모델의 성능이 높은 것을 알수 있다.
3.2 Abstractive Question Answering
RAG 모델의 경우 단순히 QA 모델에서 검색하는 능력을 벗어나서, 자유로운 형식에 대한 추상적인 질문에 대한 답변도 가능하다.
RAG의 언어 생성 능력을 판단 하기 위해서 NLG model중 MSMARCO NLG task v2.1를 사용하였다고 하였다. 해당 테스트에서는 각 질문에 대해서 10개의 최상 단락을 가져오고, 답변 출처의 원문 또한 anootated되어있다고 하였다.
답변에 필요한 특정 정보를 가진 gold passage를 이용하였을때 SotA 모델의 성능이 나온다라고 하였다. RAG모델의 경우
1) 답변에 필요한 Gold passage에 접근이 가능하다.
2) 많은 답변이 Gold passage 접근 없이 답변이 불가능하다는점
3) 모든 질문들이 Wikipedia 만을 사용해서는 답변할 수 없다는 점
의 시사점을 보아 SotA 모델의 성능에 거의 근접한 것을 확인할 수 있었다. 또한 RAG를 이용하여 생성한 답변이 Hallucination을 덜 일으키며, 더욱 다양하다.
3.3 Jeopardy Question Generation
open-domain에 등록되지 않은 QA 의 질문들 또한 테스트하여, 텍스트 생성에 중점을 맞춰 질문을 생성하는 능력을 보았다. Jeopardy는 주어진 정보에 대한 사실들을 바탕으로 질문을 생성해주는 과정을 얘기한다.
예를들면 "The World Cup"의 답변을 가지는 "In 1986 Mexico scored as the first country to host this international sports competition twice."라는 질문 결과를 이끌어 낼 수 있어야 한다.
위의 Table 2를 확인해보면, 질문을 생성해내는 능력에 대해서 RAG가 뛰어나다는 것을 확인할 수 있다.
3.4 Fact Verificaiton
FEVER은 답변의 데이터의 출처가 어디인지 True, False, 모르는지의 여부또는 부족한지 Classification하는 과정이다. 이러한 모델은 RAG가 gneration 측면이 아닌 classification에 대한 성능을 측정한다. 우리는 FEVER 클래스 라벨을 총 3개로 하여 (supports, refutes, or not enough info) 분류를 진행하였다.
Table 2를 확인해보면 72.5%의 정확성으로 sota에 비해 다른 목적을 가지고 있으메도 충분히 높은 것을 확인할 수 있다.